1. Projektziel
Ziel ist ein einfacher, reproduzierbarer und automatisierter Test für HTTP-basierte Services.
- Überprüfung der Erreichbarkeit eines Services
- Messung der Latenz über einen Zeitraum
- Erkennung von funktionalen und technischen Fehlern
- Erzeugung von Logs und einem JSON-Report als “Beweis”
2. Motivation – Warum dieses Projekt?
Typische Herausforderungen
- Manuelle Tests sind zeitaufwendig und wiederholen sich
- Fehler sind schwer reproduzierbar (“Works on my machine”)
- Bei einem FAIL fehlt oft Kontext (Logs, Zeitpunkt, Status)
Was das Skript liefert
- Automatisierte Testausführung mit klaren Kriterien
- Einheitliche Logs (Konsole + Datei)
- JSON-Report: Kennzahlen + alle Einzelmessungen
3. Architekturübersicht
Das Skript startet den Service nicht selbst. Es übernimmt die Rolle eines Test-Clients, der beobachtet, misst und dokumentiert. Der Service kann lokal laufen.
4. Ablauf – Was passiert wirklich?
Start & Parameter
Das Skript wird über CLI gestartet. Parameter definieren “Was”, “Wie lange” und “Wie streng” getestet wird.
Logging Initialisierung
Es wird in die Konsole und in eine Datei geloggt. So sind Testläufe später nachvollziehbar.
Stability Test Loop
- HTTP GET senden (probe)
- Latenz messen (ms)
- Status prüfen (2xx = OK)
- Optional: Expected-Text im Body prüfen
- Ergebnis speichern + OK/FAIL loggen
- Warten (Interval) → nächster Durchlauf
Auswertung + Report
Am Ende werden Kennzahlen berechnet (Availability, p50/p95 etc.) und ein JSON-Report erzeugt.
Docker Logs
Wenn der Service in Docker läuft und ein Containername angegeben wird, werden die letzten Logzeilen gesammelt und in den Report eingebettet.
5. Implementierung – Wichtige technische Entscheidungen
Technologie-Stack
- Python – Lesbarkeit & schnelle Anpassung
- requests – stabile HTTP Requests
- logging – standardisierte Logs
- dataclasses – klare Struktur pro Ergebnis
- JSON – teamfähiges Reporting
Qualitätsprinzipien
- Reproduzierbar: gleiche Parameter → gleicher Test
- Robust: Fehler werden erfasst, nicht “verschluckt”
- Teamfähig: Logs + Report als Evidenz
- Erweiterbar: Basis für CI-Integration
6. Resultate – Success & Failure Cases
✅ Erfolgsfall
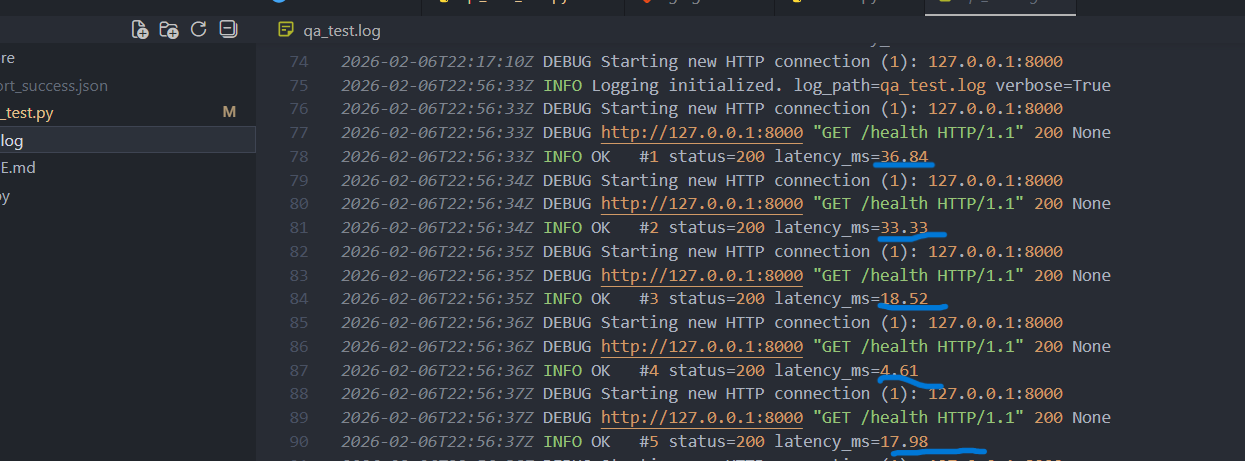
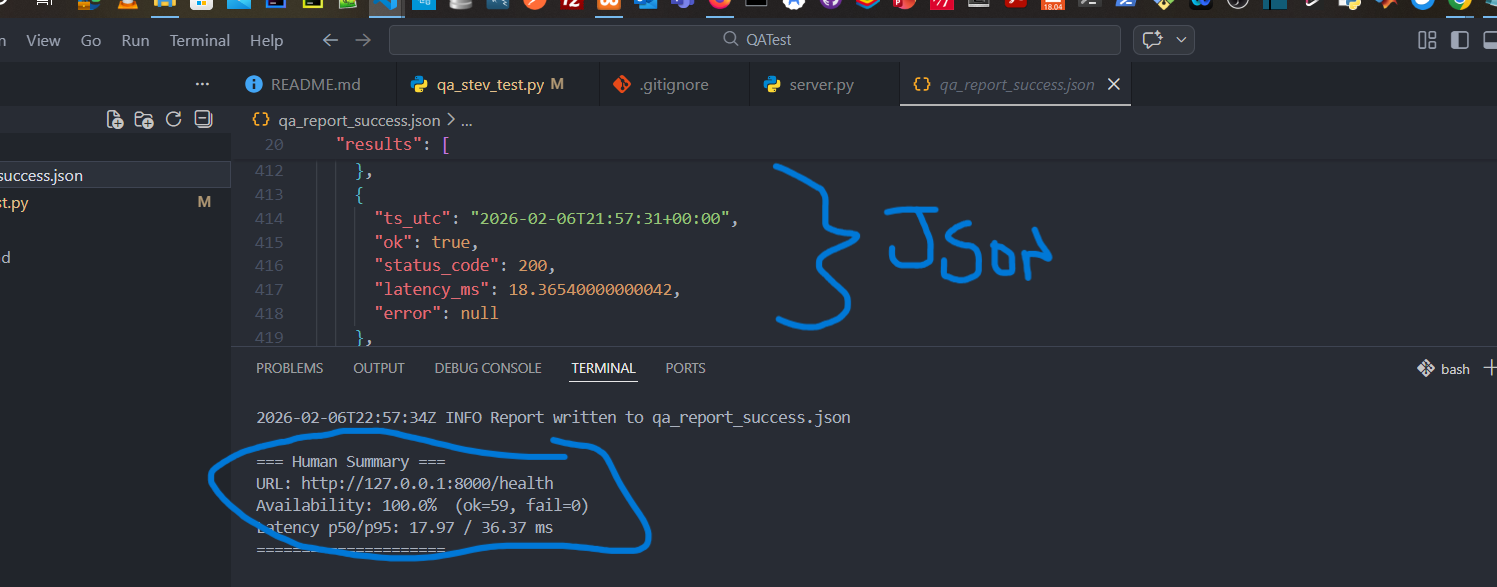
Beispiel: gültiger Endpoint /health liefert 200 + Body enthält OK.
- Status: 200
- Availability: 100%
- p50/p95: messbar (z.B. ~15–20ms lokal)
- Report:
summary+resultsvorhanden
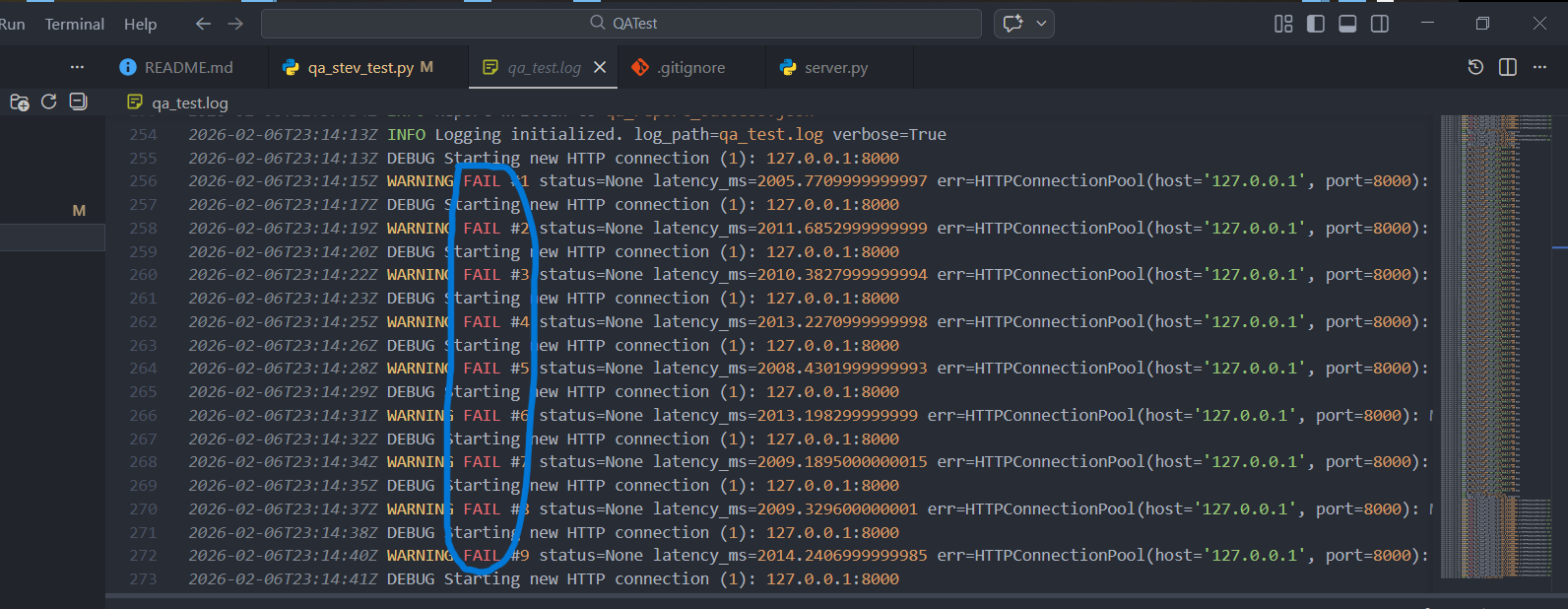
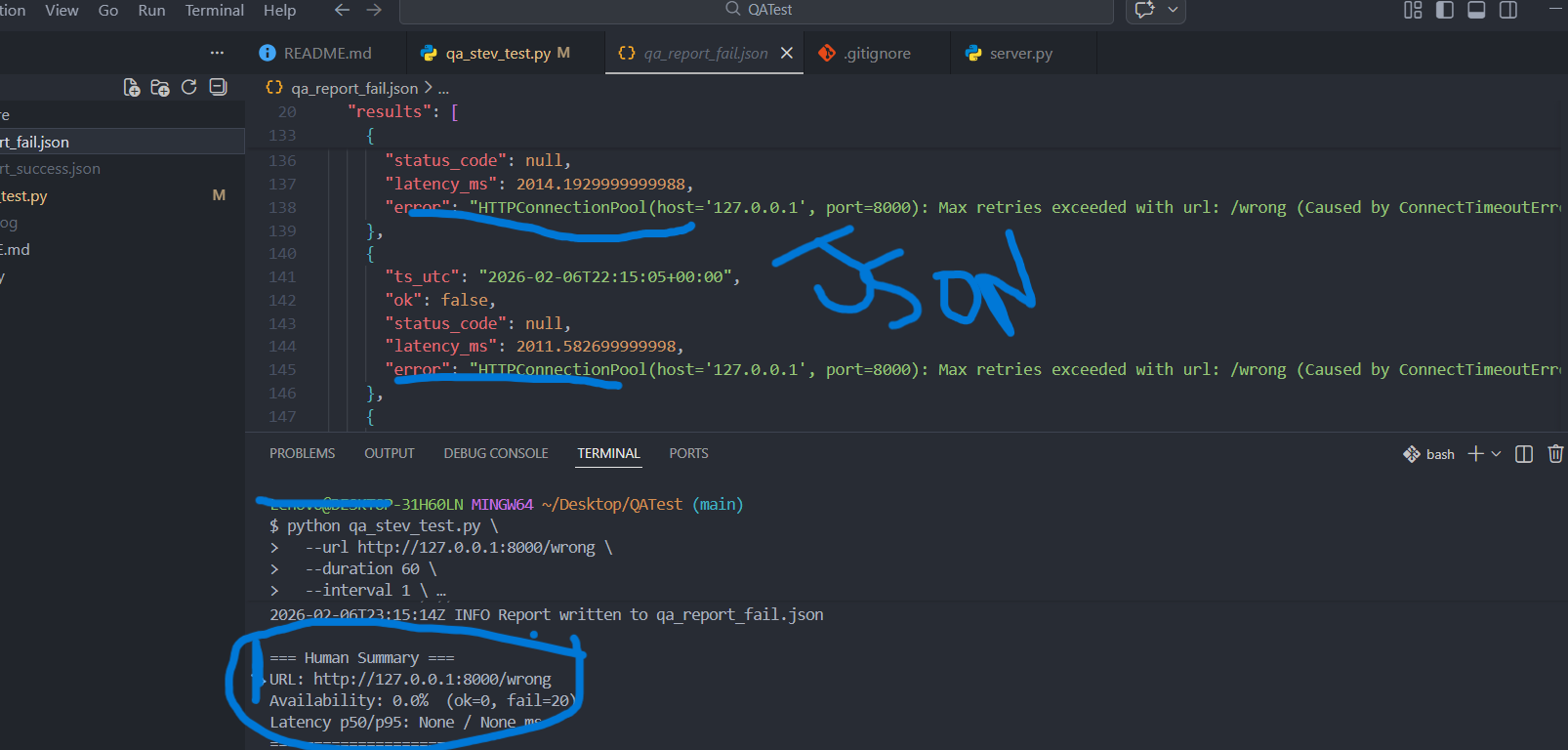
❌ Fehlerfall
Beispiel: ungültiger Endpoint /wrong liefert 404.
- Status: 404
- Availability: 0%
- p50/p95: None (weil keine OK-Requests)
- Fehlertext: z.B.
Expected 'OK' not found
Beispiel-Ausführung
pip install requests
# Erfolgsfall
python qa_test.py --url http://127.0.0.1:8000/health --duration 10 --interval 1 --timeout 2 --expected "OK"
# Fehlerfall
python qa_test.py --url http://127.0.0.1:8000/wrong --duration 6 --interval 1 --timeout 2 --expected "OK"
Unterschied zwischen localhost und 127.0.0.1 – Einfluss auf die Latenz
Während der Tests ist aufgefallen, dass sich die gemessene Latenz deutlich
unterscheidet, je nachdem ob der Service über localhost oder
127.0.0.1 angesprochen wird.
localhost
-
localhostist ein Hostname, kein direktes Netzwerkziel -
Der Name wird zuerst über die Namensauflösung aufgelöst
(
/etc/hostsoder DNS) -
Auf vielen Systemen wird
localhostzuerst auf::1(IPv6) gemappt - Dadurch kann zusätzlicher Overhead entstehen (IPv6 → IPv4 Fallback)
127.0.0.1
-
127.0.0.1ist eine direkte IPv4 Loopback-Adresse - Keine Namensauflösung notwendig
- Der Netzwerk-Stack wird direkter angesprochen
- In der Regel geringere und stabilere Latenz
Auswirkung auf die gemessene Latenz
localhostHöhere und schwankendere Latenzen (~2000 ms in den Tests), da zusätzliche Schritte in der Namensauflösung und im Netzwerk-Stack durchlaufen werden.
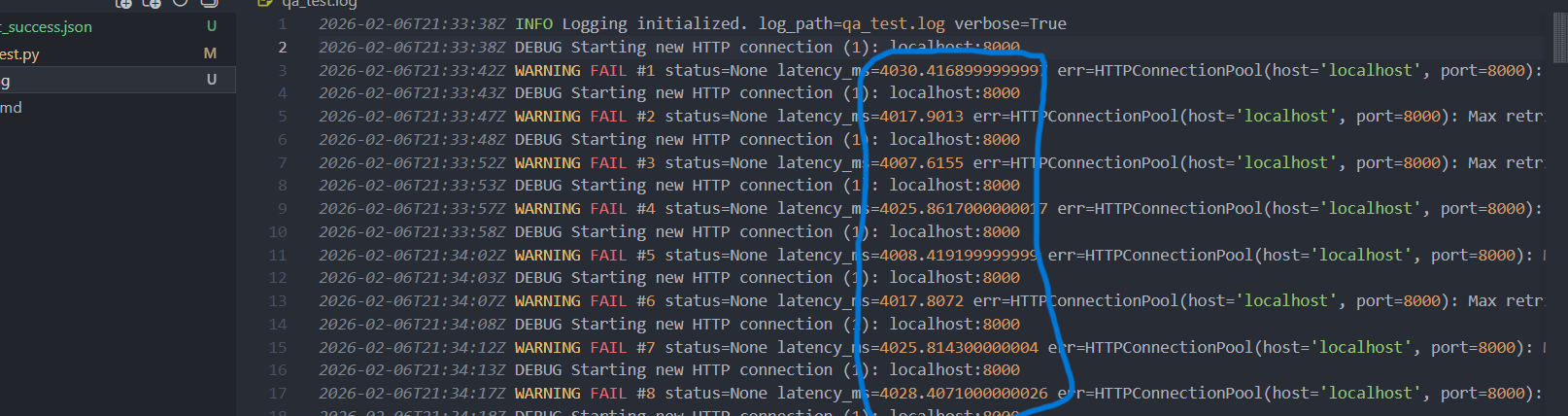
127.0.0.1Deutlich geringere und stabilere Latenzen (~10–20 ms), da der Service direkt über die Loopback-Adresse angesprochen wird.
Fazit:
Für präzise Latenz- und Stabilitätstests sollte bevorzugt
127.0.0.1 verwendet werden, da es den Netzwerk-Overhead minimiert
und realistischere Aussagen über die tatsächliche Performance des Services erlaubt.
7. Mögliche Verbesserungen
Technische Erweiterungen
- Bessere Fehlerklassifikation (Netzwerk vs. Applikation)
- Unterstützung für HTTPS/Zertifikate (falls benötigt)
QA / Reporting
- CSV Export zusätzlich zu JSON
- Nur bei FAIL automatisch Docker-Logs anhängen
8. Verbesserung – Fehlerklassifikation (Netzwerk vs. Applikation)
In der Praxis ist ein „FAIL“ allein oft nicht genug. Entscheidend ist, warum es fehlschlägt: Ist es ein Netzwerk-/Infrastrukturproblem (Timeout, DNS, Connection refused) oder ein Applikationsproblem (404/500) bzw. ein Validierungsproblem (200 OK, aber falscher Inhalt)?
Schnellere Root-Cause Analyse
- Network: DNS/Timeout/Connection Error → eher Infra/Netzwerk
- Application: 4xx/5xx → eher Endpoint/Backend/Config
- Validation: 2xx aber Expected-Text fehlt → Contract/Business-Logik
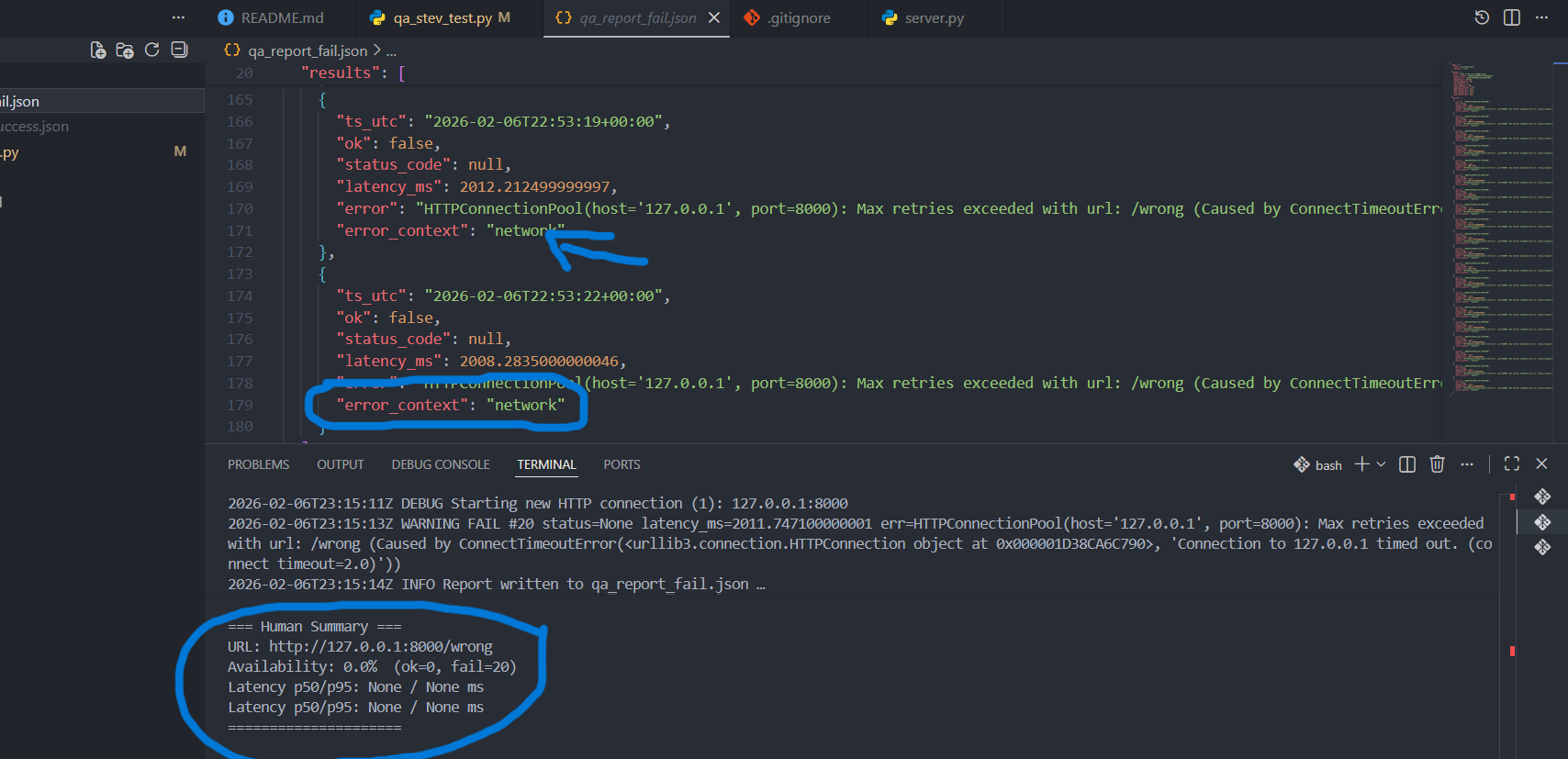
Erweiterung des Result-Objekts
Pro Request wird zusätzlich ein Feld error_context gespeichert
(z.B. network, application, validation).
# Beispiel (Konzept)
Result(
timestamp=...,
latency_ms=...,
status_code=...,
...,
error_context: Optional[str] = None
)
# Fehlerfall(Fehlerklassifikation)
python qa_test.py --url http://127.0.0.1:8000/wrong --duration 6 --interval 1 --timeout 2 --expected "OK"
Dieses Projekt habe ich bewusst gewählt, weil es zentrale technische Aufgaben abdeckt, die auch im Umfeld der Industrie-Komponenten relevant sind: Stabilität, Verfügbarkeit, Messbarkeit und Diagnose.
- Industrielle Komponente = vernetztes System: muss dauerhaft erreichbar und zuverlässig sein.
- Mein Test prüft genau das: HTTP-Erreichbarkeit, Latenz (p50/p95) und Stabilität über Zeit.
- Fehlerklassifikation: Unterscheidung zwischen
network,applicationundvalidationhilft, Ursachen schneller einzugrenzen (Infrastruktur vs. Service vs. Konfiguration).